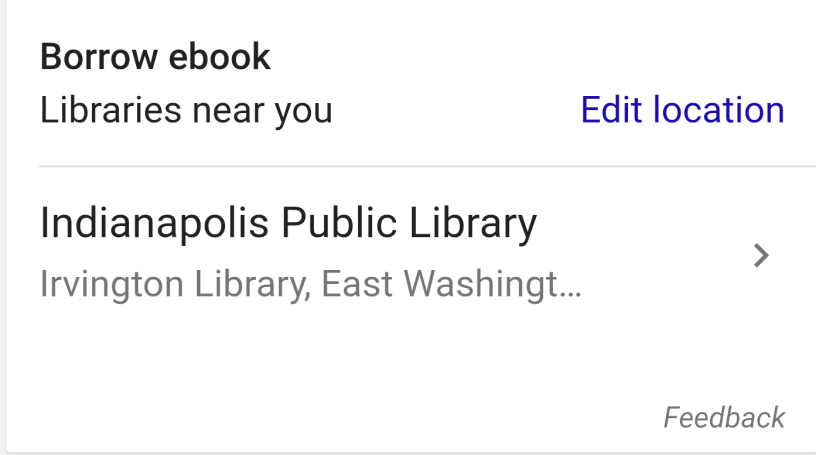
The Verge reports that Google has added local library ebook listings to its standard search interface when searching on books.
 It works, too. When I search on a book I know that my local public library does carry in ebook format on my phone (that being Grumpy Old Rock Star, a frequently hilarious book of anecdotes by Yes keyboard player Rick Wakeman), it shows right up—along with about two screens’ worth of links to various stores that carry the book in different formats, an option to “follow” the book so that stories about it appear in my swipe-left-from-homescreen Google Feed, and a link to its listing on Google Books.
It works, too. When I search on a book I know that my local public library does carry in ebook format on my phone (that being Grumpy Old Rock Star, a frequently hilarious book of anecdotes by Yes keyboard player Rick Wakeman), it shows right up—along with about two screens’ worth of links to various stores that carry the book in different formats, an option to “follow” the book so that stories about it appear in my swipe-left-from-homescreen Google Feed, and a link to its listing on Google Books.
The results are also there on the desktop, though organized a little differently—instead of being in line with the results, the links are in a small sidebar at the right. It’s the sort of thing you might not immediately notice because your eye skips over it, assuming it to be an ad of some kind. (Which, in part, it is.)
 When I click the link, it takes me to the book’s page on my local library’s Overdrive subdomain, with the option to borrow (or place a hold if all the library’s copies are already checked out).
When I click the link, it takes me to the book’s page on my local library’s Overdrive subdomain, with the option to borrow (or place a hold if all the library’s copies are already checked out).
In any case, it’s nice that Google’s directing people to local libraries along with all the local ebook stores. It’s good to remind people that a free alternative to ebook stores exists, even if they could have done a bit more to make that option stand out than just dropping it in as a fairly inobvious text link.

Now if only Google could be persuaded to have bookshelves or collection capability for GPB, everything would be dandy. It’s infuriating that Google doesn’t think that people who read ebooks wouldn’t need this capability….
LikeLike
Reblogged this on Chris The Story Reading Ape's Blog.
LikeLike